6 am: our peak time for analytical thinking
Our mode of thinking changes at different times of the day and follows a 24-hour pattern, according to new findings published in PLOS ONE. University of Bristol researchers were able to study our thinking behaviour by analysing seven-billion words used in 800-million tweets.
Researchers in Artificial Intelligence and in Medicine used AI methods to analyse aggregated and anonymised UK twitter content sampled every hour over the course of four years across 54 of the UK’s largest cities to determine if our thinking modes change collectively.
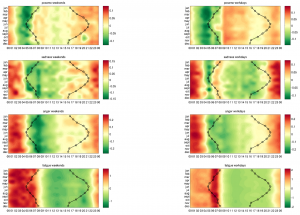
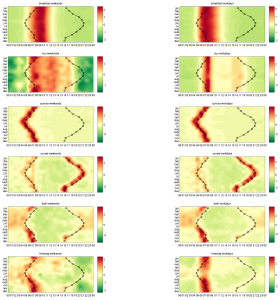
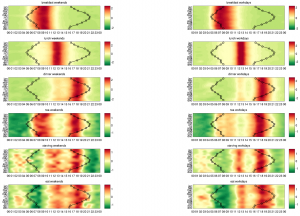
The researchers were able to reveal different emotional and cognitive modalities in our thoughts by identifying variations in language through tracking the use of specific words across the twitter sample which are associated with 73 psychometric indicators, and are used to help interpret information about our thinking style.
At 6 am, analytical thinking was shown to peak, the words and language at this time were shown to correlate with a more logical way of thinking. However, in the evenings and nights this thinking style changed to a more emotional and existential one.
Although 73 different psychometric quantities were tracked, the team found there were just two independent underlying factors that explained most of the temporal variations across the data.

The first factor, with a peak expression time starting at around 5 am to 6 am, linked with measures of analytical thinking through the high use of nouns, articles and prepositions, which has been related, in other studies, to intelligence, improved class performance and education. This early-morning period also shows increased concern with achievement and power. At the opposite end of the spectrum, the researchers find a more impulsive, social, and emotional mode.
The second factor has a peak expression time starting at 3 am to 4 am, the aggregated twitter content found this time to be correlated with the language of existential concerns but anticorrelated with expression of positive emotions.
Overall, the study discovered strong evidence that our language changes dramatically between night and day, reflecting changes in our concerns and underlying cognitive and emotional processes. These shifts also occur at times associated with major changes in neural activity and hormonal levels, suggesting possible relations with our circadian clock. Furthermore, the study revealed both cognitive and emotional states change in a predictable way during the 24 hours.

Professor Nello Cristianini, Professor of Artificial Intelligence and the project lead, said: “The analysis of media content, when done correctly, can reveal useful information for both social and biological sciences. We are still trying to learn how to make the most of it.”
Professor Stafford Lightman, Professor of Medicine and a neuroendocrinology expert at Bristol Medical School, and one of the study’s authors, added: “Circadian rhythms are a major feature of most systems in the human body, and when these are disrupted they can result in psychiatric, cardiovascular and metabolic disease. The use of media data allows us to analyse neuropsychological parameters in a large unbiased population and gain insights into how mood-related use of language changes as a function of time of day. This will help us understand the basis of disorders in which this process is disrupted.”
Paper
‘Diurnal Variations of Psychometric Indicators in Twitter Content’ by Fabon Dzogang, Stafford Lightman, Nello Cristianini in PLOS ONE [PubMed].
Media Coverage
English Language
https://www.thetimes.co.uk/article/morning-glory-x0nh6g536
https://www.forbes.com/sites/andreamorris/2018/06/20/big-data-social-media-study-reveals-our-cognitive-emotional-patterns/
http://www.dailymail.co.uk/sciencetech/article-5861695/Study-800-million-tweets-finds-daily-cycles-thinking.html
https://www.express.co.uk/news/uk/977382/britain-happier-morning-night-twitter-social-media-study-research-university-of-bristol
https://www.standard.co.uk/news/uk/britain-is-a-nation-of-morning-people-tweets-reveal-a3868261.html
http://www.dnaindia.com/technology/report-twitter-reveals-distinct-daily-cycles-in-our-thought-patterns-2627661
http://www.dailyecho.co.uk/news/national/16303694.Analytical_thinking_peaks_at_6am__according_to_study_of_800_million_tweets/
https://www.deccanherald.com/international/twitter-reveals-distinct-daily-cycles-our-thought-patterns-676118.html
Italian
http://www.repubblica.it/tecnologia/social-network/2018/06/21/news/siamo_razionali_di_giorno_emotivi_di_notte_anche_il_pensiero_ha_il_suo_bioritmo_lo_dimostra_twitter-199621681/?ref=search
http://www.lescienze.it/news/2018/06/20/news/variazione_stili_pensiero_giorno_notte_tweet-4022389/
German
https://www.n-tv.de/wissen/
https://www.morgenpost.de/web-
https://science.orf.at/
https://www.heise.de/newsticker/meldung/Studie-zur-Twitternutzung-Morgens-analytische-Tweets-abends-emotionale-4088581.html
http://www.nachrichten.at/nachrichten/web/Studie-Morgens-wird-eher-analytisch-getwittert-abends-emotional;art122,2930953
http://www.sueddeutsche.de/news/wissen/wissenschaft-morgens-wird-eher-analytisch-getwittert-abends-emotional-dpa.urn-newsml-dpa-com-20090101-180621-99-814772
https://www.abendblatt.de/ratgeber/multimedia/article214648201/Twitter-Nutzer-haben-morgens-anderen-Sprachstil-als-abends.html
https://www.noz.de/deutschland-welt/digitale-welt/artikel/1358191/wann-twitter-nutzer-am-emotionalsten-sind
https://futurezone.at/digital-life/trumps-twitter-verhalten-ist-in-der-frueh-besonders-abnormal/400054541
http://www.digitalfernsehen.de/Studie-Morgens-wird-analytisch-getwittert-abends-emotional.166317.0.html
https://www.nau.ch/unterhaltung/socialmedia/2018/06/21/twitter-morgens-wird-vernunftig-abends-emotional-65355334
Spanish
http://www.lavanguardia.com/vida/20180620/45293311213/el-modo-de-pensar-cambia-en-el-diasegun-el-analisis-de-800-millones-de-tuits.html
https://www.heraldo.es/noticias/sociedad/2018/06/20/la-forma-pensar-cambia-largo-del-dia-1250492-310.html
https://elcomercio.pe/tecnologia/ciencias/estudios-cientificos-pensar-cambia-dependiendo-momento-dia-noticia-529445
https://www.elpais.com.uy/vida-actual/pensar-cambia-dia-analisis-millones-tuits.html
http://www.infosalus.com/salud-investigacion/noticia-twitter-revela-modo-pensar-cambia-dia-siguen-patron-24-horas-20180621072942.html
https://www.larazon.es/tecnologia/los-tuits-revelan-nuestro-ritmo-de-pensamiento-EJ18777300
http://www.diarioeldia.cl/tendencias/modo-pensar-cambia-en-dia-segun-confirma-analisis-800-millones-tuits
http://www.antena3.com/noticias/ciencia/estudio-800-millones-tuits-revela-que-modo-pensar-humano-diferente-segun-momentos-dia_201806205b2a9c310cf22a63b11b02ef.html
http://www.elmostrador.cl/agenda-pais/2018/06/20/como-cambia-el-modo-de-pensar-en-el-dia-segun-el-analisis-de-800-millones-de-tuits/
http://ecos.la/8/ciencia_tecnologia/2018/06/20/24424/el-modo-de-pensar-de-una-persona-cambia-segun-el-momento-del-dia/
http://www.yucatan.com.mx/imagen/nuestra-forma-de-pensar-cambia-a-lo-largo-del-dia
Slovenian
http://www.delo.si/novice/znanoteh/zjutraj-na-twitterju-analiticno-zvecer-custveno-in-impulzivno-63361.html
https://www.sta.si/2527583/raziskava-zjutraj-so-tviti-predvsem-analiticni-zvecer-pa-custveni